
14. K 近邻回归算法实现与应用#
14.1. 介绍#
K 近邻算法实验中,我们学习了将其用于分类问题的解决思路。实际上,K 近邻亦可用于回归分析预测。本次挑战中,你将完成对 K 近邻算法改造,将其应用于回归分析。
14.2. 知识点#
K 近邻回归介绍
K 近邻回归实现
14.3. 内容回顾#
回顾我们在 K 近邻实验中学习过的内容。当使用 K 近邻算法完成分类任务时,需要的步骤有:
数据准备:通过数据清洗,数据处理,将每条数据整理成向量。
计算距离:计算测试数据与训练数据之间的距离。
寻找邻居:找到与测试数据距离最近的 K 个训练数据样本。
决策分类:根据决策规则,从 K 个邻居得到测试数据的类别。
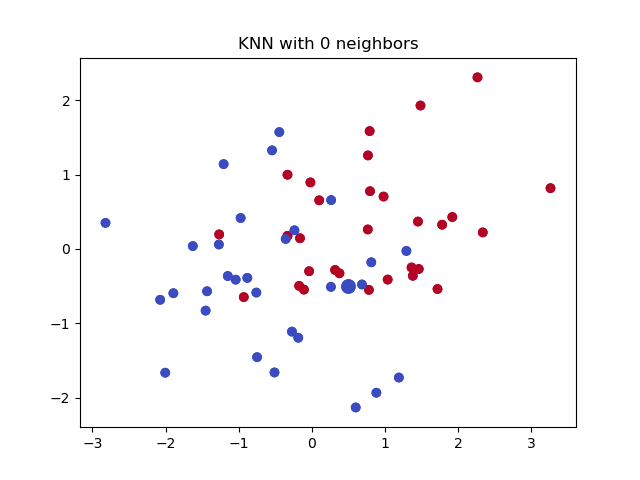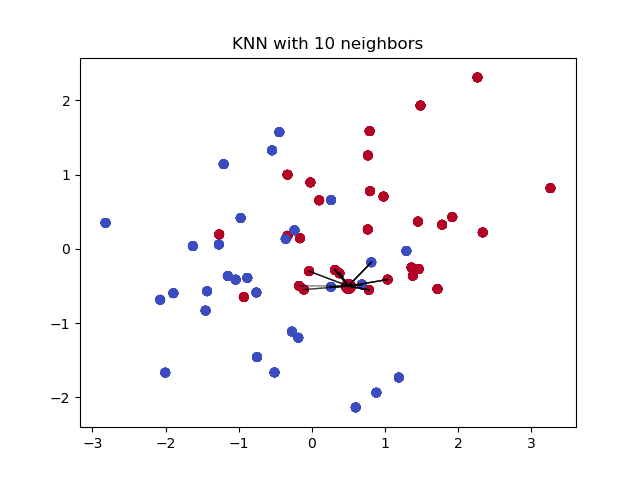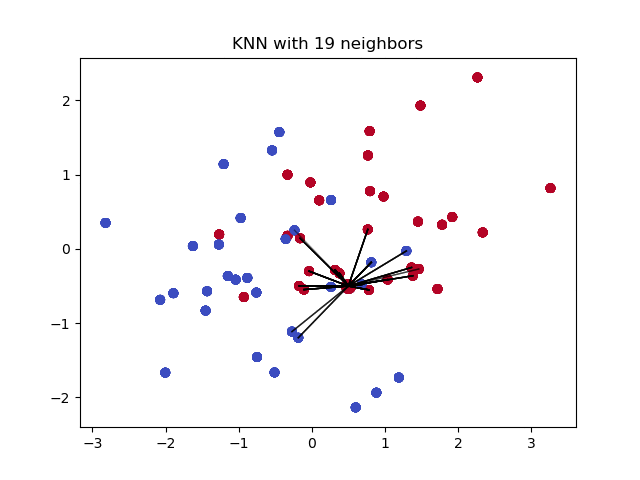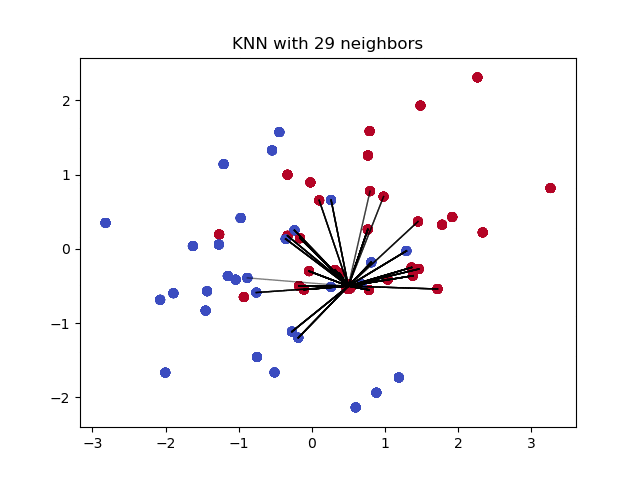
其中,「决策分类」是决定未知样本类别的关键步骤。那么,当我们将 K 近邻算法用于回归预测时,实际上只需要将这一步修改为适合于回归问题的流程即可。
分类问题:根据 K 个邻居的类别,多数表决得到未知样本的类别。
回归问题:根据 K 个邻居的目标值,计算平均值得到未知样本的预测值。
K 近邻回归算法图示如下:
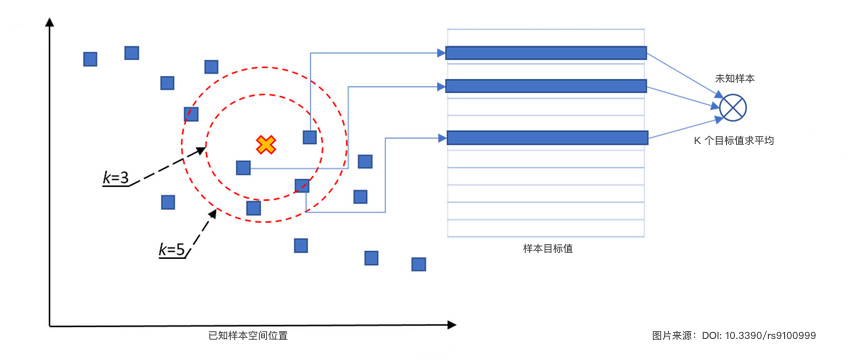
接下来,你需要根据上面的图示和说明,实现 K 近邻回归算法,并用示例数据进行验证。
Exercise 14.1
挑战:根据上述图示和说明,实现 K 近邻回归算法。
规定:距离计算使用欧式距离公式,部分代码可以参考实验内容。
def knn_regression(train_data, train_labels, test_data, k):
"""
参数:
train_data -- 训练数据特征 numpy.ndarray.2d
train_labels -- 训练数据目标 numpy.ndarray.1d
test_data -- 测试数据特征 numpy.ndarray.2d
k -- k 值
返回:
test_labels -- 测试数据目标 numpy.ndarray.1d
"""
### 代码开始 ### (≈ 10 行代码)
test_labels = None
### 代码结束 ###
return test_labels
Solution to Exercise 14.1
def knn_regression(train_data, train_labels, test_data, k):
"""
参数:
train_data -- 训练数据特征 numpy.ndarray.2d
train_labels -- 训练数据目标 numpy.ndarray.1d
test_data -- 测试数据特征 numpy.ndarray.2d
k -- k 值
返回:
test_labels -- 训练数据目标 numpy.ndarray.1d
"""
### 代码开始 ### (≈ 10 行代码)
test_labels = np.array([]) # 创建一个空的数组用于存放预测结果
for X_test in test_data:
distances = np.array([])
for each_X in train_data: # 使用欧式距离计算数据相似度
d = np.sqrt(np.sum(np.square(X_test - each_X)))
distances = np.append(distances, d)
sorted_distance_index = distances.argsort() # 获取按距离大小排序后的索引
k_labels = train_labels[sorted_distance_index[:k]]
y_test = np.mean(k_labels)
test_labels = np.append(test_labels, y_test)
### 代码结束 ###
return test_labels
下面,我们提供一组测试数据。
import numpy as np
# 训练样本特征
train_data = np.array(
[[1, 1], [2, 2], [3, 3], [4, 4], [5, 5], [6, 6], [7, 7], [8, 8], [9, 9], [10, 10]]
)
# 训练样本目标值
train_labels = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
运行测试
# 测试样本特征
test_data = np.array([[1.2, 1.3], [3.7, 3.5], [5.5, 6.2], [7.1, 7.9]])
# 测试样本目标值
knn_regression(train_data, train_labels, test_data, k=3)
期望输出
array([2., 4., 6., 7.])
如果你觉得这些内容对你有帮助,可以通过 微信赞赏码 或者 Buy Me a Coffee 请我喝杯咖啡。
{kind=link}